At a recent DataKind SF event, I was rather intrigued by the challenges faced in investigating wage theft and other labor violations not just throughout the nation, but also specific to California and the Bay Area regions. At first, and probably like a lot of you, I had little idea what “wage theft” and other labor violations really entailed. Upon some reading, and in correspondence with some very motivated domain experts from the Stanford Center for Integrated Facility Engineering and the San Francisco Dept. of Labor Wage and Hour Division, the extent and impact of this problem began to impress upon me. This NY Times article captures the gist of the issue well. Withholding overtime pay, paying below minimum wage, skimming wages off paychecks, violations against under-age workers (child labor!), visa abuse, etc. are all forms of theft and abuse that have a big impact to at-risk workers, their families, and make life harder than it already is.
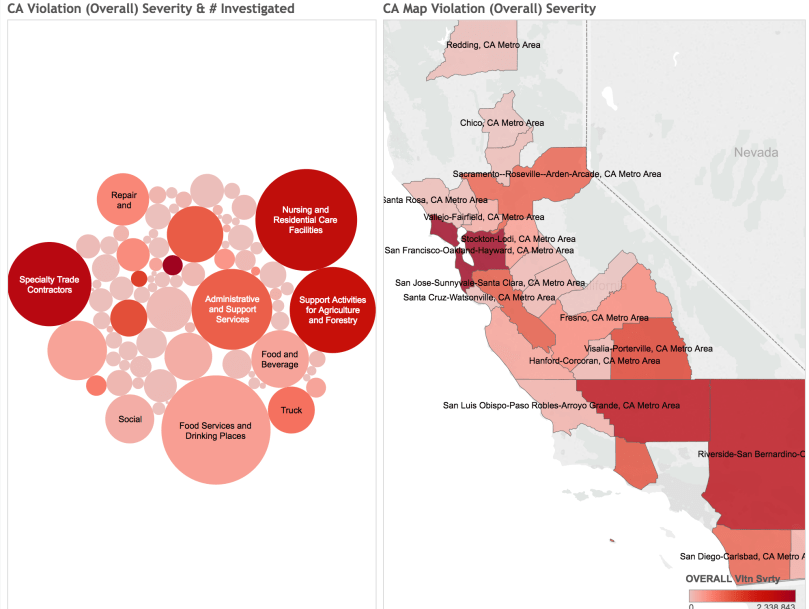
The Wage and Hour Division (WHD) has done a nice job of summarizing some impact statistics around this problem. Meanwhile, the Department of Labor has put together a dataset of all known (investigated and closed) cases of violations nationwide at this D.O.L. Enforcement portal. The “Wage and Hour Compliance Action Data” is what I’ll be looking at, specifically.











