
What is a Cult Movie?
I love cult films! What’s not to love about Sam Jackson on a plane with a bunch of steroid-induced snakes unleashed on passengers? Yeah, the movie’s as weird as it sounds, and yet it leaves me with a yearning to discuss it, to quote it years after its release, develop a weird fascination for Sam Jackson, and makes me curious about [the late] director David Ellis. I feel connected to any discussions around it and enjoy quips that reference scenes and dialogs in the movie. Others like me might even wear paraphernalia from the movie, years later. It’s an attachment – an agglomerate set of feelings and actions – that’s distinct from an appreciation of a really good indie movie.





What then, is a cult movie? Consider some literature from AMC’s filmsite:
Cult Films have limited but very special appeal. Cult films are usually strange, quirky, offbeat, eccentric, oddball, or surreal, with outrageous, weird, unique and cartoony characters or plots, and garish sets. They are often considered controversial because they step outside standard narrative and technical conventions. They can be very stylized, and they are often flawed or unusual in some striking way.
Wow, those are a lot of subjective measures. I mean it’s not like I can measure “quirky” in terms of milligrams now is it? Well played, interweb… it seems as if I must outwit you to try and study this phenomenon better; which brings me to the point:
The problem statement! I’ll break it into two parts…
- Figure out a good measure of what makes a movie a cult phenomenon. (this post)
- Knowing this, can I use a movie’s pre-release information to predict whether or not it will become a cult phenom? (near future)
Good Data Hunting
Now that I’ve somewhat defined my question, I’m allowed to wonder about the kind of data I need to answer it… movie data! Genius! Immediately, names such as IMDB, RottenTomatoes, and BoxOfficeMojo come to mind. But there really is a sh*t ton of information to sift through on these sites. Where do I begin? For this, I go back to my problem statement: I need a measure of a movie’s “cult-ness”, I’m looking for some kind of quantification. Okay, getting warmer: Let’s do some more research around cult movie literature, again on filmsite:
Many cult films fared poorly at the box office when first shown, but then achieved cult-film status, developing an enduring loyalty and following among fans over time, often through word-of-mouth recommendations. … There’s no hard-and-fast rule or checklist to gauge what makes a cult film. … It’s often a matter of opinion. One viewer’s cult film may not be judged the same by another viewer.
I’m not discouraged by the grim conclusion on the subjectivity of cult phenomenon because there are a couple of important clues in the above excerpt (bolded): Cult movies tend to have lower opening box office revenues, but they tend to gain an “enduring loyalty… over time”. Now I’m starting to get a sense of what data I should hunt for. Anything else? Yes! More research suggests (intuitively) that there are certain directors (think, David Lynch) that are more prone to making movies that develop cult followings than others. Unstructured, context based, research of this sort yields the following factors of interest that might contribute to the cult phenom:
- Initial box office revenue (opening weeks, or even weekend, perhaps?)
- Fan popularity over time: This is a tricky one! Cast the net too wide and the entire Star Wars genre may be up for consideration. Furthermore, what do I use to measure Fan popularity? # of reviews over time (not enough for older movies)? Repeated showings in dedicated independent theaters would be a good one – but there seem to be no reliable sources of such data.
- Here’s an idea. Assuming that film lifetime revenue is some indicator of continued interest in the movie (repeated showings in theaters, tv, merchandise), why not gauge this instead? It’s worth a shot especially since revenue data is easily available.
- Directors!
- Actors? I can associate maybe two Sam Jackson movies with a “cult” status (you get to guess the other one 🙂 )
- Heck why not throw Production studios in the mix as well?
- # of theaters showing! Most cult movies tend to open with a limited release.
Oh, let’s stick to American movies, to start with.
Data Scraping

Armed with Python’s ugly BeautifulSoup (as Emily, my Data Scientist colleague, so aptly put it) and some regex-fu, the first thing I need to do is actually find a list of movies going back far enough. Wikipedia to the rescue here! Next, BoxOfficeMojo.com seems to have a nice set of specs by movie. So here are the steps I execute to download data for about 8,500 movies – after counting all the movies for which step 3 below turned up ‘not found’ – (with links to my python code):
- Construct Wiki URL structure for every year since 1970
- From the movie year page, scrape list of all movies released that year
- For each movie, construct BoxOfficeMojo URLs by inferring canonical URL structure
- Scrape circled data points for each movie from Bomojo, if found.
Data Cleaning – Data Janitors Rejoice!
…and now we have a sh*t load of raw data! Specifically, I have around 8,500 movies in my dataset from 1970 – 2012 with about 15 relevant features. Oddly, and I don’t admit this openly enough, I do get a weird sort of masochistic pleasure just molding and beating large amounts of data into shape. Here’s a snippet of what I have to work with:

Python pandas provides me with all the muscle power I need to wrestle my data into shape. Quick shout out: As a dplyr enthusiast I got to concede some ground to pandas as I get more and more impressed with the sheer number of manipulations that can be done using this module. Nevertheless, these are the steps I follow, and feel free to get your code-porn fix here:
- Adjust all my revenue numbers for inflation:
- I adjust Total Gross Revenue, and Opening Weekend Revenue by scraping the values off of BoxOfficeMojo’s neat little ticket price inflation table on this page
- I then adjust Production Budget using the CPI numbers provided by the Bureau of Labor Statistics.
- Engineer new feature: Lifetime Revenue (Total Gross – Opening Weekend Revenue). I have to assume at this point that BoMoJo’s Total Gross number is a decent approximation of what a movie’s made since its release.
- Take care of some bread and butter data manipulations such as coerce date fields, categorize non-numeric columns, convert Runtime into minutes, regex the sh*t out of text fields that should be numeric
- After all this is done, I need some inkling of which movies are commonly accepted to be “cult”. Now, I could manually go through all 8,500 of them, but being the competent Data Janitor that I am, I choose to scrape, then merge multiple semi-authority lists of “cult” movies online such as this one on IMDB. This enables me to engineer a brand new feature: isCult, a simple flag indicating whether or not a movie has been designated as cult by the all knowing inter-web!

More Cleaning: Impute Missing Numeric Values
I always reserve a special place in my cold, data-driven heart for treating missing values. If data cleaning gives me some sort of guilty pleasure then I downright have a crush on strategies for imputing missing values. For this dataset, I’m dealing with around 40% missing numbers for production budget. Far too many to just drop. And far too sensitive to other factors to be merely filled in by an overall aggregate (such as mean of production budget). One of my go to techniques in such scenarios, where the numeric feature is sensitive to many other variables, I like to use a tiered, group-aggregate-transform strategy. Here’s what I mean in this case:
# prod_budget. There are 3610 missing values!!! Sensitive to imputing, but this could also be an important feature.
mov.prod_budget_ADJ[mov.prod_budget_ADJ==0]=np.nan
mov.prod_budget_ADJ.fillna(mov.groupby(['year','distributor','genre_bomojo'] ['prod_budget_ADJ'].transform('mean'), inplace=True)
mov.prod_budget_ADJ.fillna(mov.groupby(['distributor','genre_bomojo'])['prod_budget_ADJ'].transform('median'), inplace=True)
#these cut down nans to more than half. will drop the rest, too much noise at just the distributor level...
mov.prod_budget_ADJ.dropna(inplace=True)
What I’ve basically done above is for every missing production budget, I’ve asked if [group] in the same year, the same distributor has made one or more movies of the same genre… if yes… then use the [aggregate] mean of these production budgets as our missing value [transform]. As you’d expect, this doesn’t happen very often, so I then go the next level up on my tier, which is to group only by distributor and genre across all the years – you can see how this starts to become a risky assumption. So I dare not go to the outer level. I stop here and drop the rest of my NAs. In this way I’ve at least retained a good chunk of missing values and can be confident that this is a fair approximation of their empirical values.
the Real Cult Movies… Please Stand Up
And after all that, I can finally try to quantify this phenomenon. Here’s what I’m thinking; the higher this index the more prone to attaining cult status a movie will be, so what are some of the things that cause it to go higher or lower? Well, we already know that cult movies have weak opening:

Literature also tells us that these movies generate consistent following over time. Earlier, we decided to use the Lifetime Revenue as a rough gauge for this notion (more lifetime rev. is good for the index). But we want an idea of consistent revenue, and for this reason we break this number in terms of revenue / year (every year since release):
![index \alpha [ (lifetime revenue)/\delta years since release) ]/ (opening weekend revenue)](https://s0.wp.com/latex.php?latex=index+%5Calpha+%5B+%28lifetime%C2%A0revenue%29%2F%5Cdelta+years+since+release%29+%5D%2F+%28opening+weekend+revenue%29&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
And I want to enforce the notion that movies prone to going cult open with a limited release (reward the index for lesser number of theaters opened):
![index \alpha [ (lifetime revenue)/\delta years since release) ]/ [(opening weekend revenue)*(num_{theaters})]](https://s0.wp.com/latex.php?latex=index+%5Calpha+%5B+%28lifetime%C2%A0revenue%29%2F%5Cdelta+years+since+release%29+%5D%2F+%5B%28opening+weekend+revenue%29%2A%28num_%7Btheaters%7D%29%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
There is a problem here, this formula will always reward newer movies that haven’t had a chance to establish their lifetime revenue/year rate. We really want to reward movies that have consistently generated year over year revenue (think of how many times Office Space was picked up by TV networks, or how Shawshank Redemption VHS and DVD rentals built its reputation since its release). So let’s throw a rewarding parameter in there that rewards older movies that have shown consistent income over time. Finally, we get:
![index \alpha [ (lifetime revenue)/\delta years since release) ] * log_2(\delta years since release)/ [(opening weekend revenue)*(num_{theaters})]](https://s0.wp.com/latex.php?latex=index+%5Calpha+%5B+%28lifetime%C2%A0revenue%29%2F%5Cdelta+years+since+release%29+%5D+%2A+log_2%28%5Cdelta+years+since+release%29%2F+%5B%28opening+weekend+revenue%29%2A%28num_%7Btheaters%7D%29%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Let’s see how well this index does on the overall dataset. Here are the highest scoring movies, 17 movies, minus the one duplicate:

What I really need this index to do, is at least distinguish debatable cult phenoms from the more mainstream counterparts. Let’s take a look at how the index does by splitting the

dataset on IMDB’s cult list (isCult) indicator and taking a sample of 400 movies from the non cult set.
We see that “Drama”, “War” and “Adventure” produce crazy variation in the index. But Adventure and War don’t have that many observations, compared to other genres, so let’s take a fresh look without these two:

Interestingly, the index seems to do a decent job of showing more variation in most genres (green) except in “Period”, “Crime”, “Thriller”, and to an extent “Comedy”. There are clearly other factors such as Directors and Production Studios (which we haven’t considered) that might confound the index somewhat.
Is the Cult Index Significantly Different?
Okay, I have a nice little index that seems to do a decent job of making some noise around movies that might be cult candidates. But the operating word here is “seems”. Overall, it seems to work:
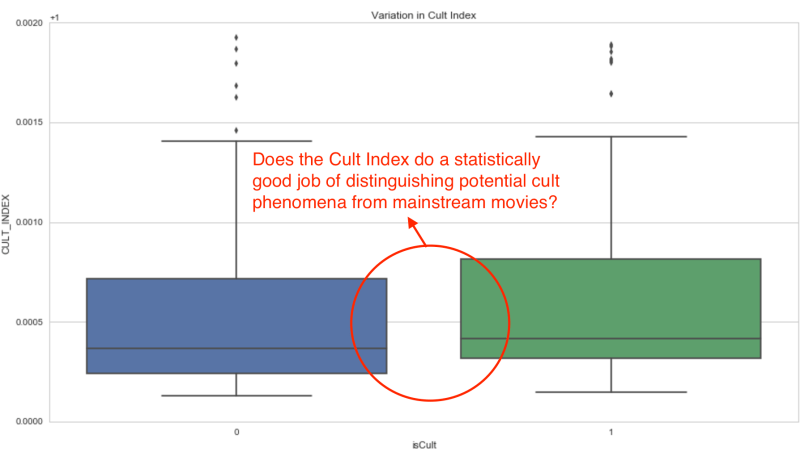
What I’m interested in is this: Given many, many… many movies, can this Cult Index consistently differentiate cult candidates from mainstream movies? To answer this I’ll assume that there is no prior knowledge, and use the frequentist’s approach to testing the hypothesis based on the sample we have.
Null Hypothesis: The average cult index for mainstream movies is the same as the average cult index for cult candidates (that is, I start with the assumption that the index makes no difference, and attempt to disprove it).
Alternate Hypothesis: The average cult index for mainstream movies is not the same as the average cult index for cult candidates.
This makes the case for a student’s t-test for two independent groups with non-constant variance.
Mainstream Group Mean, Variance: 1.008786, 0.001324 Cult Group Mean, Variance: 1.013930, 0.002341
We use the sample mean and variances to estimate our standard error, then go on to find the t-statistic using Python’s scipy.stats.ttest_ind() function. Here’s what we get:
Ttest_indResult(statistic=-1.7699125936459499, pvalue=0.077119762937860575)
There is a 7.7% chance that the means between the two groups are the same. This is not trivial and so we fail to reject the null hypothesis!
Conclusion
Since I have not been able to show that my Cult Index will be different a significant number of times for all the movies I’m grouping as potential cult candidates, it doesn’t make much sense to use this index as the basis for prediction in a linear regression problem. If I were to further explore this route, I’ll have to refine my Cult Index formula with more domain knowledge.
To this point, part II of this article should then approach this as a classification problem to try and find out all the factors that impact the cult definition of a movie.
If you have any ideas to share, questions around how I went about this, or just want to chat about your cult favorites, don’t hesitate to reach out or comment below. Thanks for sticking with this exercise!
- Project Code on Github
- Project Deck (Keystone Presentation)
- Thanks to my Data Science mentors Rumman Choudhury and Joel Wesley for their input on this project.
- Twitter Me
- LinkedIn… Me
End of Part 1.
(Part 2 Coming Soon.)

I see you don’t monetize your page, don’t waste your traffic, you can earn extra bucks every month because you’ve
got hi quality content. If you want to know how to make extra money, search
for: Boorfe’s tips best adsense alternative
LikeLike
Hi senpai,
Yes, the second quote is also from filmsite (I ought to have made it more explicit, I’ll remedy that soon).
An astute observation for the second part! Yes, I think normalizing the “index” by genre should be at least another exploratory step in the exercise. I did remove the genres for which the counts were very low, but what you’re suggesting is good practice anyway.
Speaking of which, and to your point about weightage of each genre, I intend to approach this as a classification problem in Part 2. I expect my Logistic Regression classifier to “learn” the ideal weights in the training set, so that’ll definitely shed more light on the genres’ impact on “cultness”.
LikeLike
What’s the source of the second quote about the ‘definition’ of a cult movie – is that also AMC’s filmsite?
Also, given that we have a number of movies generally identified as cult movies, can you determine any other criteria? For instance, there are lots of comedy cult films compared to war cult films – may just be a factor of the relative total number of films made in each genre, but could you include other factors like genre as a weighting?
LikeLiked by 1 person